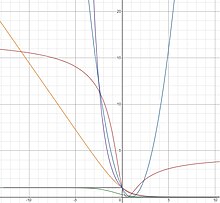
Функции согласованных потерь по Байесу: потеря ноль-единица (серый), дикая потеря (зеленый), логистическая потеря (оранжевый), экспоненциальная потеря (фиолетовый), касательная потеря (коричневый), квадратная потеря (синий)
В машинном обучении и математической оптимизации , потеря функции для классификации являются вычислительно осуществимые функции потерь , представляющие цену , уплаченную за неточность прогнозов в задачах классификации (проблемы определения , к какой категории конкретное наблюдение принадлежит). Учитывая пространство всех возможных входов (обычно ) и набор меток (возможных выходов), типичная цель алгоритмов классификации состоит в том, чтобы найти функцию, которая наилучшим образом предсказывает метку для данного входа . Однако из-за неполной информации, шума в измерениях или вероятностных компонентов в базовом процессе одно и то же может генерировать разные . В результате цель проблемы обучения - минимизировать ожидаемые потери (также известные как риск), определяемые как






![{\ displaystyle I [f] = \ displaystyle \ int _ {{\ mathcal {X}} \ times {\ mathcal {Y}}} V (f ({\ vec {x}}), y) p ({\ vec {x}}, y) \, d {\ vec {x}} \, dy}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a681d2ec2b4e729a58045cd58dd718b1cc91b3d6)
где - заданная функция потерь, а - функция плотности вероятности процесса, который сгенерировал данные, что эквивалентно может быть записано как



В рамках классификации несколько часто используемых функций потерь записываются исключительно в терминах произведения истинной метки и предсказанной метки . Следовательно, они могут быть определены как функции только одной переменной , так что с подходящим образом выбранной функцией . Они называются функциями потерь на основе маржи . Выбор функции потерь на основе маржи равносилен выбору . Выбор функции потерь в рамках этой структуры влияет на оптимум, который минимизирует ожидаемый риск.






В случае бинарной классификации можно упростить расчет ожидаемого риска на основе указанного выше интеграла. Конкретно,
![{\ displaystyle {\ begin {align} I [f] & = \ int _ {{\ mathcal {X}} \ times {\ mathcal {Y}}} V (f ({\ vec {x}}), y ) p ({\ vec {x}}, y) \, d {\ vec {x}} \, dy \\ [6pt] & = \ int _ {\ mathcal {X}} \ int _ {\ mathcal { Y}} \ phi (yf ({\ vec {x}})) p (y \ mid {\ vec {x}}) p ({\ vec {x}}) \, dy \, d {\ vec { x}} \\ [6pt] & = \ int _ {\ mathcal {X}} [\ phi (f ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) p (-1 \ mid {\ vec {x}})] p ({\ vec {x}}) \, d {\ vec {x}} \ \ [6pt] & = \ int _ {\ mathcal {X}} [\ phi (f ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) (1-p (1 \ mid {\ vec {x}}))] p ({\ vec {x}}) \, d {\ vec {x}} \ end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b790a75d49d31c4d0b845445046bae07114894ee)
Второе равенство следует из описанных выше свойств. Третье равенство следует из того факта, что 1 и −1 - единственные возможные значения для , а четвертое - потому что . Термин в скобках называется условным риском.
![{\ displaystyle [\ phi (е ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) (1- p (1 \ mid {\ vec {x}}))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/976cb6e601d74f6154999611a9c8113ee189b6c4)
Можно найти минимизатор для , взяв функциональную производную последнего равенства по и установив производную равной 0. Это приведет к следующему уравнению
![Если]](https://wikimedia.org/api/rest_v1/media/math/render/svg/8213b3ec4b7c34969992d3f12dd96b830c9082ef)


что также эквивалентно установке производной условного риска равной нулю.
Учитывая бинарный характер классификации, естественным отбором для функции потерь (при условии равной стоимости ложных срабатываний и ложных отрицаний ) будет функция потерь 0-1 ( индикаторная функция 0–1 ), которая принимает значение 0, если прогнозируемая классификация равна истинному классу или 1, если прогнозируемая классификация не соответствует истинному классу. Этот выбор смоделирован

где указывает ступенчатую функцию Хевисайда . Однако эта функция потерь невыпуклая и негладкая, и решение оптимального решения представляет собой NP-трудную задачу комбинаторной оптимизации. В результате лучше заменить суррогаты функции потерь, которые поддаются обработке для часто используемых алгоритмов обучения, поскольку они имеют удобные свойства, такие как выпуклость и гладкость. В дополнение к их вычислительной управляемости, можно показать, что решения проблемы обучения с использованием этих суррогатов потерь позволяют восстановить фактическое решение исходной проблемы классификации. Некоторые из этих суррогатов описаны ниже.

На практике распределение вероятностей неизвестно. Следовательно, использование обучающего набора независимо и одинаково распределенных точек выборки


взятые из выборки данных , стремятся минимизировать эмпирический риск
![{\ displaystyle I_ {S} [f] = {\ frac {1} {n}} \ sum _ {i = 1} ^ {n} V (f ({\ vec {x}} _ {i}), y_ {i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f11407df44b1dc610c3fe193ce436cc33520ffe5)
как показатель ожидаемого риска. (См. Более подробное описание в теории статистического обучения .)
Последовательность Байеса
Используя теорему Байеса , можно показать, что оптимальный , т. Е. Тот, который сводит к минимуму ожидаемый риск, связанный с потерей нуля или единицы, реализует правило оптимального решения Байеса для задачи двоичной классификации и имеет форму

-
 .
.
Функция потерь называется калиброванной по классификации или согласованной по Байесу, если ее оптимальность такова, что она является оптимальной в соответствии с правилом принятия решения Байеса. Байесовская согласованная функция потерь позволяет нам найти байесовскую функцию оптимального решения , напрямую минимизируя ожидаемый риск и без необходимости явно моделировать функции плотности вероятности.

Для выпуклой потери маржи можно показать, что байесовская непротиворечивость тогда и только тогда, когда она дифференцируема в 0 и . Тем не менее, этот результат не исключает существования невыпуклых байесовских согласованных функций потерь. Более общий результат утверждает, что байесовские согласованные функции потерь могут быть сгенерированы с использованием следующей формулировки


-
![{\ Displaystyle \ фи (v) = С [е ^ {- 1} (v)] + (1-е ^ {- 1} (v)) С '[е ^ {- 1} (v)] \; \; \; \; \; (2)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ba1d9d0d51b1c65272af55aa780a285afa90d9d) ,
,
где - любая обратимая функция такая, что и - любая дифференцируемая строго вогнутая функция такая, что . Таблица-I показывает сгенерированные байесовские согласованные функции потерь для некоторых примеров выбора и . Обратите внимание, что потери Savage и Tangent не являются выпуклыми. Было показано, что такие невыпуклые функции потерь полезны при работе с выбросами при классификации. Для всех функций потерь, полученных из (2), апостериорная вероятность может быть найдена с помощью функции обратимой связи как . Такие функции потерь, в которых апостериорная вероятность может быть восстановлена с помощью обратимого звена, называются собственными функциями потерь .







Таблица-I
| Имя потери
|

|
|
|

|
| Экспоненциальный
|

|

|

|

|
| Логистика
|

|
![{\ Displaystyle {\ гидроразрыва {1} {\ log (2)}} [- \ eta \ log (\ eta) - (1- \ eta) \ log (1- \ eta)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e609e1c16646f7a8a99eb51b64fb94416a6a425)
|

|

|
| Квадратный
|

|

|

|

|
| дикий
|

|

|
|
|
| Касательная
|

|
|

|

|
Единственный минимизатор ожидаемого риска, связанный с сгенерированными выше функциями потерь, может быть непосредственно найден из уравнения (1) и показан как равный соответствующему . Это справедливо даже для невыпуклых функций потерь, что означает, что алгоритмы на основе градиентного спуска, такие как повышение градиента, могут использоваться для построения минимизатора.
Правильные функции потерь, маржа потерь и регуляризация
Для правильных функций потерь запас потерь можно определить как и показать, что он напрямую связан со свойствами регуляризации классификатора. В частности, функция потерь с большим запасом увеличивает регуляризацию и дает лучшие оценки апостериорной вероятности. Например, маржа потерь может быть увеличена для логистических потерь путем введения параметра и записи логистических потерь в виде, где меньше увеличивает маржу потерь. Показано, что это прямо эквивалентно уменьшению скорости обучения при повышении градиента, где уменьшение улучшает регуляризацию усиленного классификатора. Теория проясняет, что, когда используется скорость обучения , правильная формула для получения апостериорной вероятности теперь .






В заключение, выбирая функцию потерь с большим запасом (меньшим ), мы увеличиваем регуляризацию и улучшаем наши оценки апостериорной вероятности, что, в свою очередь, улучшает кривую ROC окончательного классификатора.
Квадратная потеря
Хотя функция квадратичных потерь чаще используется в регрессии, ее можно переписать как функцию и использовать для классификации. Его можно сгенерировать с помощью (2) и Таблицы-I следующим образом.

![{\ Displaystyle \ phi (v) = C [е ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = 4 ({\ frac {1} {2}} (v + 1)) (1 - {\ frac {1} {2}} (v + 1)) + (1 - {\ frac {1} {2}} (v + 1)) (4-8 ({\ frac {1} {2}} (v + 1))) = (1-v) ^ {2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7cdde8f62987c985c1028a98d8c24682dfe0c2d7)
Квадратная функция потерь бывает выпуклой и гладкой. Однако функция квадратичных потерь имеет тенденцию чрезмерно наказывать выбросы, что приводит к более медленным скоростям сходимости (в отношении сложности выборки), чем для функций логистических потерь или потерь на шарнирах. Кроме того, функции, которые дают высокие значения для некоторых, будут плохо работать с функцией квадратичных потерь, поскольку высокие значения будут строго наказываться, независимо от того, совпадают ли знаки и .


Преимущество функции квадратичных потерь состоит в том, что ее структура позволяет легко перекрестную проверку параметров регуляризации. В частности, для регуляризации Тихонова можно найти параметр регуляризации с помощью перекрестной проверки с исключением по одному за то же время, что и для решения одной задачи.
Минимизатор квадратичной функции потерь можно найти непосредственно из уравнения (1) как

Логистическая потеря
Функция логистических потерь может быть сгенерирована с использованием (2) и Таблицы-I следующим образом.
![{\ Displaystyle {\ begin {align} \ phi (v) & = C [f ^ {- 1} (v)] + \ left (1-f ^ {- 1} (v) \ right) \, C ' \ left [f ^ {- 1} (v) \ right] \\ & = {\ frac {1} {\ log (2)}} \ left [{\ frac {-e ^ {v}} {1+ e ^ {v}}} \ log {\ frac {e ^ {v}} {1 + e ^ {v}}} - \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ log \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ right] + \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ left [{\ frac {-1} {\ log (2)}} \ log \ left ({\ frac {\ frac { e ^ {v}} {1 + e ^ {v}}} {1 - {\ frac {e ^ {v}} {1 + e ^ {v}}}}} \ right) \ right] \\ & = {\ frac {1} {\ log (2)}} \ log (1 + e ^ {- v}). \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fd7a4c1188c935bcf5f76e4063f97034fb54e39)
Логистические потери являются выпуклыми и линейно растут для отрицательных значений, что делает их менее чувствительными к выбросам. Логистическая потеря используется в алгоритме LogitBoost .
Минимизатор для функции логистических потерь может быть непосредственно найден из уравнения (1) как

Эта функция не определена, когда или (стремится к ∞ и −∞ соответственно), но предсказывает плавную кривую, которая растет при увеличении и равна 0, когда .




Легко проверить, что логистические потери и двоичные кросс-энтропийные потери (логарифмические потери) на самом деле одинаковы (с точностью до константы мультипликатора ). Потеря кросс-энтропии тесно связана с расхождением Кульбака – Лейблера между эмпирическим распределением и предсказанным распределением. Потеря кросс-энтропии широко распространена в современных глубоких нейронных сетях .

Экспоненциальный убыток
Экспоненциальная функция потерь может быть сгенерирована с использованием (2) и Таблицы-I следующим образом.
![{\ Displaystyle \ phi (v) = C [е ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = 2 {\ sqrt {({\ frac {e ^ {2v}} {1 + e ^ {2v}}}) (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v}}}) }} + (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v}}}) ({\ frac {1 - {\ frac {2e ^ {2v}} {1 + e ^ { 2v}}}} {\ sqrt {{\ frac {e ^ {2v}} {1 + e ^ {2v}}} (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v}) }})}}}) = e ^ {- v}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aaf52f9ceb280f470317e416a711b1e924cc1bd0)
Экспоненциальные потери являются выпуклыми и экспоненциально растут для отрицательных значений, что делает их более чувствительными к выбросам. В алгоритме AdaBoost используется экспоненциальная потеря .
Минимизатор для экспоненциальной функции потерь может быть непосредственно найден из уравнения (1) как

Дикая потеря
Потери Savage могут быть сгенерированы с использованием (2) и Таблицы-I следующим образом
![{\ displaystyle \ phi (v) = C [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = ( {\ frac {e ^ {v}} {1 + e ^ {v}}}) (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}}) + (1- { \ frac {e ^ {v}} {1 + e ^ {v}}}) (1 - {\ frac {2e ^ {v}} {1 + e ^ {v}}}) = {\ frac {1 } {(1 + e ^ {v}) ^ {2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3bc29f01f367ef3f4d6f92ce2f91827622a59b30)
Потери по Сэвиджу квазивыпуклые и ограничены для больших отрицательных значений, что делает их менее чувствительными к выбросам. Потери Savage использовались в повышении градиента и алгоритме SavageBoost.
Минимизатор для функции потерь Сэвиджа может быть непосредственно найден из уравнения (1) как

Касательная потеря
Касательные потери могут быть сгенерированы с использованием (2) и Таблицы-I следующим образом.
![{\ displaystyle {\ begin {align} \ phi (v) & = C [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1 } (v)] = 4 (\ arctan (v) + {\ frac {1} {2}}) (1 - (\ arctan (v) + {\ frac {1} {2}})) + (1 - (\ arctan (v) + {\ frac {1} {2}})) (4-8 (\ arctan (v) + {\ frac {1} {2}})) \\ & = (2 \ arctan (v) -1) ^ {2}. \ end {выравнивается}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/48fc53108e779ecf1e26b0725b3873944fcd9644)
Потери касательной квазивыпуклые и ограничены для больших отрицательных значений, что делает их менее чувствительными к выбросам. Интересно, что потеря касательной также назначает ограниченный штраф для точек данных, которые были классифицированы «слишком правильно». Это может помочь предотвратить перетренированность набора данных. Потеря касательной использовалась в повышении градиента , алгоритме TangentBoost и чередующихся лесах решений.
Минимизатор для функции потерь по касательной можно найти непосредственно из уравнения (1) как

Потеря шарнира
Функция потерь шарнира определяется как , где - функция положительной части .
![{\ Displaystyle \ фи (\ ипсилон) = \ макс (0,1- \ ипсилон) = [1- \ ипсилон] _ {+}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/068b33990cb9f189f89c1c4b775424ff8bd5fade)
![{\ Displaystyle [а] _ {+} = \ макс (0, а)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eb205e8d8fd29396410d5c3764b95f1323335f6e)
![{\ Displaystyle В (е ({\ vec {x}}), y) = \ max (0,1-yf ({\ vec {x}})) = [1-yf ({\ vec {x}}) )] _ {+}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bec5bd9d55a0fa201d877181b995db28b17f9827)
Потеря на шарнире обеспечивает относительно жесткую, выпуклую верхнюю границу индикаторной функции 0–1 . В частности, потеря на шарнире равна индикаторной функции 0–1, когда и . Кроме того, минимизация эмпирического риска этих потерь эквивалентна классической формулировке для машин опорных векторов (SVM). Правильно классифицированные точки, лежащие за границами границ опорных векторов, не штрафуются, тогда как точки в пределах границ границ или на неправильной стороне гиперплоскости штрафуются линейно по сравнению с их расстоянием от правильной границы.


Хотя функция потерь шарнира является выпуклой и непрерывной, она не является гладкой (не дифференцируемой) в точке . Следовательно, функция потерь шарнира не может использоваться с методами градиентного спуска или методами стохастического градиентного спуска, которые полагаются на дифференцируемость по всей области. Однако потеря на шарнире имеет субградиент при , что позволяет использовать методы субградиентного спуска . SVM, использующие функцию потерь в шарнире, также могут быть решены с помощью квадратичного программирования .

Минимизатор для функции потерь шарнира равен

when , что соответствует функции индикатора 0–1. Этот вывод делает потерю петли весьма привлекательной, поскольку можно установить границы разницы между ожидаемым риском и знаком функции потерь петли. Потери на шарнире не могут быть выведены из (2), так как они не обратимы.


Обобщенная потеря плавности шарнира
Обобщенная функция потерь гладкого шарнира с параметром определяется как


где

Он монотонно увеличивается и достигает 0, когда .

Смотрите также
Рекомендации




